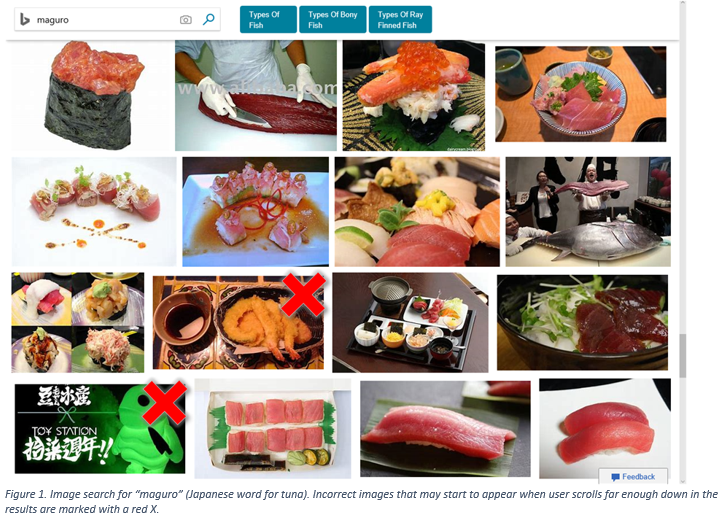
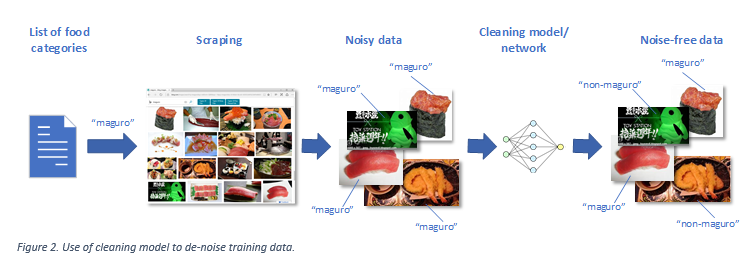
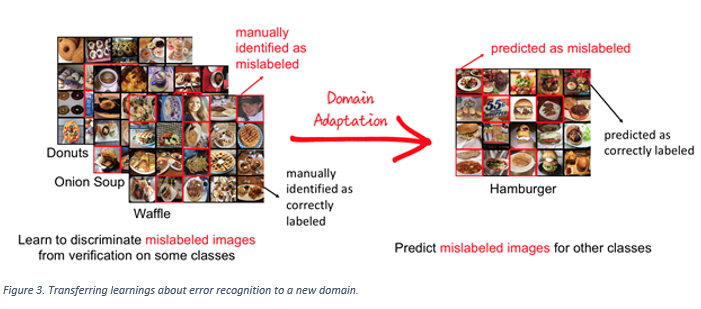
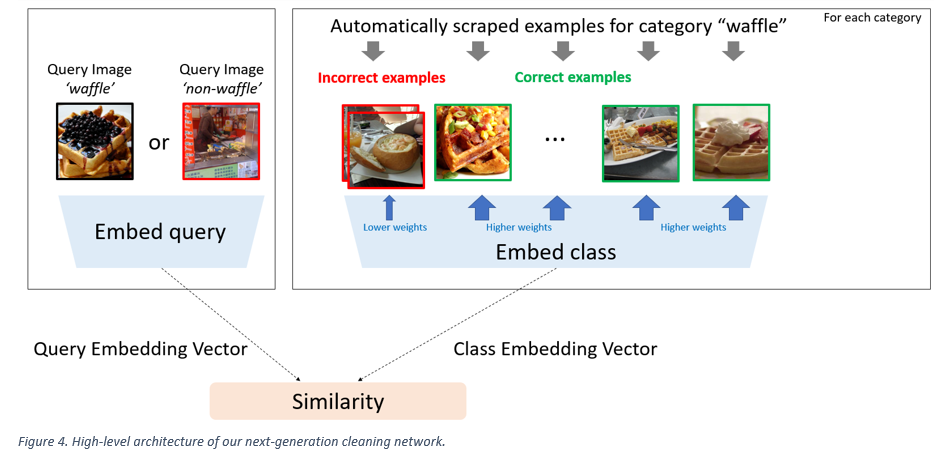
This post describes the container images that we produce and update for you, that you can use with Docker, Kubernetes and other systems. When you are using .NET and Docker together, you are probably using the official .NET container images from Microsoft. We’ve made many improvements over the last year to the .NET images that make it easier for you to containerize .NET applications.
Last week during DockerCon 2018, I posted an update about Using .NET and Docker Together. It demonstrates how you can use Docker with .NET, for production, development and testing. Those scenarios are all based on the .NET container images on Docker Hub.
Faster Software Delivery
Docker is a game changer for acquiring and using .NET updates. Think back to just a few years ago. You would download the latest .NET Framework as an MSI installer package on Windows and not need to download it again until we shipped the next version. Fast forward to today. We push updated container images to Docker Hub multiple times a month. Every time you pull .NET images, you are getting updated software, an update to .NET and/or the underlying operating system, either Windows or Linux.
This new model of software delivery is much faster and creates a much stronger connection between software producer and consumer. It also gives you more control, but requires a bit more knowledge on how you acquire software, through Docker. It is important that you understand the Docker repos and tags that the software provider — in this case Microsoft — uses so that you get the exact versions and updates you want. This post is intended to provide you with the information you need to select the best versions of .NET images and tags for your needs.
Official images from Docker
Docker maintains official images, for operating systems and application platforms. These images are maintained by a combination of Docker, community developers and the operating system or application platform maintainers who are expert in Docker and the given technology (like Alpine).
Official images are:
- Correctly and optimally configured.
- Regularly maintained.
- Can be shared (in memory) with other applications.
.NET images are built using official images. We build on top of Alpine, Debian, and Ubuntu official images for x64 and ARM. By using official images, we leave the cost and complexity of regularly updating operating system base images and packages like OpenSSL, for example, to the developers that are closest to those technologies. Instead, our build system is configured to automatically build, test and push .NET images whenever the official images that we use are updated. Using that approach, we’re able to offer .NET Core on multiple Linux distros at low cost and release updates to you within hours. There are also memory savings. A combination of .NET, Java, and Node.js apps run on the same host machine with the latest official Debian image, for example, will share the Debian base image in memory.
.NET Images from Microsoft
.NET images are not part of the Docker official images because they are maintained solely by Microsoft. Windows Server images, which we also build on top of, are the same. Similar to Docker official images, we have a team of folks maintaining .NET images that are expert in both .NET and Docker. This results in the same benefits as described for Docker official images, above.
We maintain .NET images with the following model:
- Push same-day image updates, when a new .NET version or base operating system image is released
- Push images to Docker Hub only after successful validation in our VSTS CI system
- Produce images that match the .NET version available in Visual Studio
- Make pre-release software available for early feedback and use on microsoft/dotnet-nightly
We rely on Docker official maintainers to produce quality images in a timely manner so that our images are always up-to-date. We know you rely on us to do the same thing for .NET. We also know that many of you automatically rebuild your images, and the applications contained within them, when a new .NET image is made available. It is very important that this process works well, enabling your applications to always be running on the latest patched version of .NET and the rest of the software stack you have chosen to use. This is part of how we work together to ensure that .NET applications are secure and reliable in production.
.NET Docker Hub Repos
Docker Hub is a great service that stores the world’s public container images. When we first started pushing images to Docker Hub, we created fine-grained repositories. Many fine-grained repos has its advantages, but discoverability is not one of them. We heard feedback that it was hard to find .NET images. To help with that, we reduced the number of repos we use. The current set of .NET Docker Hub repos follows:
.NET Core repos:
.NET Framework repos:
- microsoft/dotnet-framework – includes .NET Framework runtime and sdk images.
- microsoft/aspnet – includes ASP.NET runtime images, for ASP.NET Web Forms and MVC, configured for IIS.
- microsoft/wcf – includes WCF runtime images configured for IIS.
- microsoft/iis – includes IIS on top of the Windows Server Core base image. Works for but not optimized for .NET Framework applications. The microsoft/aspnet and microsoft/wcf repos are recommended instead for running the respective application types.
Deprecated repositories
.NET Image Tags
The image tag you use in your Dockerfile is perhaps the most important artifact within your various Docker-related assets. The tag defines the underlying software that you expect to be using when you rundocker build and that your app will be running on in production. The tag gives you a lot of control over the images you pull, but can also be a source of pain if the tag you are using doesn’t align with your needs.
There are four main options for tags, from most general to most specific:
- latest version — The
latest tag aligns with the default version of the software available from a repository (for whatever the repository maintainer considers the default – may or may not be the actual latest version). When you don’t specify a tag, your request pulls the latest tag. From one pull to the next, you might get software and/or the underlying operating system that has been updated by a major version. For example, when we shipped .NET Core 2.0, the latest tag (for Linux) jumped from .NET Core 1.1 to 2.0 and from Debian 8 to 9. Latest is great for experimentation, but not a good choice for anything else. You don’t want your application to use latest in an automated build.
- minor version — A major.minor tag, such as
2.0-runtime or 2.1-sdk, locks you to a specific family of updates of software. These example tags will receive only .NET Core 2.0 or .NET Core 2.1 updates, respectively. You can expect to get patch updates to the software and the underlying operating system when you build with docker build --pull. We recommend this form of tag for most cases. It balances the competing concerns of ease of use and the risk of updates. The 4.7.2-sdk .NET Framework tag, for example, matches this tag style.
- patch version — A major.minor.patch tag, such as
2.0.7-runtime locks you to a specific patch version of software. This is great from a predictability standpoint, but you need to update your Dockerfile every time you want to update to a new patch version. That’s a lot of work and requires quick action if you need to deploy a .NET security updates for multiple applications. The 4.7.2-sdk-20180523-windowsservercore-1803 .NET Framework tag, for example, matches this tag style. We do not update the .NET contents in patch version images, but we may push new images for the tag due to underlying base image changes. As a result, do not consider patch version tags to be immutable.
- digest — You can reference an image digest directly. This approach gives you the most predictability. Tags can and are overwritten with new images while digests cannot be. Tags can also be deleted. We recommend using digests in the case an application breaks due to an image update and you need to go back to a “last known good” image. It can be challenging to determine the digest for an image you are no longer using. You can add logging into your image building infrastructure to collect this information as an insurance policy for unforeseen breakage.
Tags are a contract on the .NET version you want and the degree of change you expect. We do our best to satisfy that contract each time we ship. We do two main things to produce quality container images: CI validation and code-review. CI validation runs on several operating systems with each pull request to .NET repos. This level of pre-validation provides us with confidence on the quality of the Docker images we push to Docker Hub.
For each major and minor .NET version, we may take a new major operating system version dependency. As I mentioned earlier, we adopted Debian 9 as the base image for .NET Core 2.0. We stayed with Debian 9 for .NET Core 2.1, since Debian 10 (AKA “Buster”) has not been released. Once we adopt an underlying operating system major version, we will not change it for the life of that given .NET release.
Each distro has its own model for patches. For .NET patches, we will adopt minor Debian releases (Debian 9.3 -> 9.4), for example. If you look at .NET Core Dockerfiles, you can see the dependency on various Linux operating systems, such as Debian and Ubuntu. We make decisions that make sense within the context for the Windows and Linux operating systems that we support and the community that uses them.
Windows versioning with Docker works differently than Linux, as does the way multi-arch manifest tags work. In short, when you pull a .NET Core or .NET Framework image on Windows, you will get an image that matches the host Windows version, if you use the mult-arch tags we expose (more on that later). If you want a different version, you need to use the specific tag for that Windows version. Some Azure services, like Azure Container Instances (ACI) only support Windows Server 2016 (at the time of writing). If you are targeting ACI, you need to use a Windows Server 2016 tag, such as 4.7.2-runtime-windowsservercore-ltsc2016 or 2.1-aspnetcore-runtime-nanoserver-sac2016, for .NET Framework and ASP.NET Core respectively.
.NET Core Tag Scheme
There are multiple kinds of images in the microsoft/dotnet repo:
- sdk — .NET Core SDK images, which include the .NET Core CLI, the .NET Core runtime and ASP.NET Core.
- aspnetcore-runtime — ASP.NET Core images, which include the .NET Core runtime and ASP.NET Core.
- runtime — .NET Core runtime images, which include the .NET Core runtime.
- runtime-deps — .NET Core runtime dependency images, which include only the dependencies of .NET Core and not .NET Core itself. This image is intended for self-contained applications and is only offered for Linux. For Windows, you can use the operating system base image directly for self-contained applications, since all .NET Core dependencies are satisfied by it.
We produce Docker images for the following operating systems:
- Windows Nano Server 2016+
- Debian 8+
- Alpine 3.7
- Ubuntu 18.04
.NET Core supports multiple chips:
Note: ARM64v8 images will be made available at a later time, possibly with .NET Core 3.0.
.NET Core tags follow a scheme, which describes the different combinations of kinds of images, operating systems and chips that .NET Core supports.
[version]-[kind]-[os]-[chip]
Note: This scheme is new with .NET Core 2.1. Earlier versions use a similar but slightly different scheme.
The following .NET Core 2.1 tags are examples of this scheme:
- 2.1.300-sdk-alpine3.6
- 2.1.0-aspnetcore-runtime-stretch-slim
- 2.1.0-runtime-nanoserver-1803
- 2.1.0-runtime-deps-bionic-arm32v7
Note: You might notice that some of these tags use strange names. “bionic” and “stretch” are the version names for Ubuntu 18.04 and Debian 9, respectively. They are the tag names used by the ubuntu and debian repos, respectively. “stretch-slim” is a smaller variant of “stretch”. We use smaller images when they are available. “nanoserver-1803” represents the Spring 2018 update of Windows Nano Server. “arm32v7” describes a 32-bit ARM-based image. ARMv7 is a 32-bit instruction set defined by ARM Holdings.
They are also short-forms of .NET Core tags. The short-forms are short in two different ways. They use two part version numbers and skip the operating system. In most cases, the short-form tags are the ones you want to use, because they are simpler, are serviced, and are multi-arch so are portable across operating systems.
We recommend you use the following short-forms of .NET Core tags in your Dockerfiles:
- 2.1-sdk
- 2.1-aspnetcore
- 2.1-runtime
- 2.1-runtime-deps
As discussed above, some Azure services only support Windows Server 2016 (not Windows Server, version 1709+). If you use one of those, you may not be able to use short tags unless you happen to only build images on Windows Server 2016.
.NET Framework Tag Scheme
There are multiple kinds of images in the microsoft/dotnet-framework repo:
- sdk — .NET Framework SDK images, which include the .NET Framework runtime and SDK.
- runtime — .NET Framework runtime images, which include the .NET Framework runtime.
We produce Docker images for the following Windows Server versions:
- Windows Server Core, version 1803
- Windows Server Core, version 1709
- Windows Server Core 2016
.NET Framework tags follow a scheme, which describes the different combinations of kinds of images, and Windows Server versions that .NET Framework supports:
[version]-[kind]-[timestamp]-[os]
The .NET Framework version number doesn’t use the major.minor.patch scheme. The third part of the version number does not represent a patch version. As a result, we added a timestamp in the tag to create unique tag names.
The following .NET Framework tags are examples of this scheme:
- 4.7.2-sdk-20180615-windowsservercore-1803
- 4.7.2-runtime-20180615-windowsservercore-1709
- 3.5-sdk-20180615-windowsservercore-ltsc2016
They are also short-forms of .NET Framework tags. The short-forms are short in two different ways. They skip the timestamp and skip the Windows Server version. In most cases, those are the tags you will want to use, because they are simpler, are serviced, and are multi-arch so are portable across Windows versions.
We recommend you use the following short-form of tags in your Dockerfiles, using .NET Framework 4.7.2 and 3.5 as examples:
- 4.7.2-sdk
- 4.7.2-runtime
- 3.5-sdk
- 3.5-runtime
As discussed above, some Azure services only support Windows Server 2016 (not Windows Server, version 1709+). If you use one of those, you may not be able to use short tags unless you happen to only build images on Windows Server 2016.
The microsoft/aspnet and microsoft/wcf using a variant of this tag scheme and may move to this scheme in the future.
Security Updates and Vulnerability Scanning
As you’ve probably picked up at this point, we update .NET images regularly so that you have the latest .NET and operating system patches available. For Windows, our image updates are similar in nature to the regular “Patch Tuesday” releases that the Windows team makes available on Windows Update. In fact, we update our Windows-based images with the latest Windows patches every Patch Tuesday. You don’t run Windows Update in a container. You rebuild with the latest container images that we make available on Docker Hub.
The update experience is more nuanced on Linux. We support multiple Linux distros that can be updated at any time. There is no specific schedule. In addition, there is usually a set of published vulnerabilities (AKA CVEs) that are unpatched, where no fix is available. This situation isn’t specific to using Linux in containers but using Linux generally.
We have had customers ask us why .NET Core Debian-based images fail their vulnerability scans. I use anchore.io for scanning and have validated the same scans that customers shared with us. The vulnerabilities are coming from the base images we use.
You can look at the same scans I look at:
One of my observations is that the scan results change significantly over time for Debian and Ubuntu. For Alpine, they remain stable, with few vulnerabilities reported.
We employ three approaches to partially mitigate challenge:
- Rebuild and republish .NET images on the latest Linux distro patch updates immediately (within hours).
- Support the latest distro major versions as soon as they are available. We have observed that the latest distros are often patched quicker.
- Support Alpine, which is much smaller, so has fewer components that can have vulnerabilities.
These three approaches give you a lot of choice. We recommend you use .NET Core images that use the latest version of your chosen Linux distro. If you have a deeper concern about vulnerabilities on Linux, use the latest patch version of the .NET Core 2.1 Alpine images. If you are still unhappy with the situation, then consider using our Nano Server images.
Using Pre-release Images
We maintain a pre-release Docker Hub repository, dotnet-nightly. Nightly builds of .NET Core 2.1 images were available in that repo before .NET Core 2.1 shipped. There are nightly builds of the .NET Core 1.x and 2.x servicing branches in that repo currently. Before long, you’ll see nightly builds of .NET Core 2.2 and 3.0 that you can test.
We also offer .NET Core with pre-release versions of Linux distros. We offered Ubuntu 18.04 (AKA “bionic”) before it was released. We currently offer .NET Core images with pre-release versions of Debian 10 (AKA “buster”) and the Alpine edge branch.
Closing
We want to make it easy and intuitive for you to use the official .NET images that we produce, for Windows and Linux. Docker provides a great software delivery system that makes it easy to stay up-to-date. We hope that you now have the information you need to configure your Dockerfiles and build system to use the tag style that provides you with the servicing characteristics and image consistency that makes sense for your environment.
We will continue to make changes to .NET container images as we receive feedback and as the Docker feature set changes. We post regular updates at dotnet/announcements. “watch” that repo to keep up with the latest updates.
If you are new to Docker, check out Using .NET and Docker Together. It explains how to use .NET with Docker in a variety of scenarios. We also offer samples for both .NET Core and .NET Framework that are easy to use and learn from.
Tell us how you are using .NET and Docker together in the comments. We’re interested to hear about the way you use .NET with containers and how you would like to see it improved.


 Emily Ley believes perfect is overrated. When life gets overly busy, rather than strive in vain to check every box every day, Ley’s approach is to scale back. Simplify. Make intentional choices. Plan purposefully. And don’t be afraid to fail.
Emily Ley believes perfect is overrated. When life gets overly busy, rather than strive in vain to check every box every day, Ley’s approach is to scale back. Simplify. Make intentional choices. Plan purposefully. And don’t be afraid to fail. I saw a tweet from a person on Twitter who wanted to know the easiest and cheapest way to get an Web Application that's in a Docker Container up to Azure. There's a few ways and it depends on your use case.
I saw a tweet from a person on Twitter who wanted to know the easiest and cheapest way to get an Web Application that's in a Docker Container up to Azure. There's a few ways and it depends on your use case.

















")
















")